
The Complete Guide to Crypto x AI
Does Web 3 have a role in AI - or is it just a gimmick?

Blockcrunch VIP is a premium research newsletter on the most important crypto projects and trends, prepared by top crypto analysts twice a month. Subscribe to Blockcrunch VIP to receive in-depth project analysis, interactive token models and exclusive AMAs from our research team - all for the price of a coffee ☕ a day.
Since the advent of ChatGPT, AI has become a global sensation, amassing a staggering 100 million users within just two months of its launch - a growth trajectory that sets a new benchmark as the fastest-growing consumer platform to date.
However, the applications of AI are not limited to generative capabilities as exemplified by language models like ChatGPT, but extend into predictive domains and more. Prime examples include autonomous driving, which relies heavily on AI for navigation and decision-making, and personalization algorithms that curate unique user experiences across digital platforms
Recently, crypto funds like Paradigm have also signaled their broadening focus to include AI, and we’ve begun seeing venture funding for AI x Web 3 projects start to heat up, such as Gensyn’s massive $43 million Series A
To help you understand all you need to know about AI x Web 3, and answer if this burgeoning intersection is fluff or has real substance, this article delves into:
Easy-to-understand overview of AI and its key components
Breakdown of what AI x Web 3 entails
Spotlight and performance analysis on 9 different Decentralized Compute and Decentralized Data projects
A Primer on AI
Before we dive further, you should first understand a few key AI concepts and terms. If you are well-versed on AI fundamentals, feel free to skip over this.
Artificial Intelligence: AI is an umbrella term for computer systems designed to mimic human intelligence and perform tasks such as learning, problem-solving, perception, and language understanding. It’s akin to a set of tools and principles guiding us to make computers or machines smart enough to perform tasks that would usually require human cognitive function.
Models: A model in the AI context is essentially a computer program that has been taught to perform a specific task. For example, ChatGPT is great at understanding and generating text outputs, while Stable Diffusion is great at generating images. You can think of it like a student who has been taught a particular subject.
Training: Just like a student, the model learns from data (examples). The training process involves presenting the model with tons of data, and adjusting its internal parameters so that it can better perform its task
Inferencing: After a model has been trained and finetuned, it can begin doing its job such as answering your questions. The act of producing an output after a given input is called inferencing because the model doesn’t actually understand users’ input like a human does. Instead, the model makes a prediction based on what is the likely statistical output using knowledge gained from training data
For example, when you ask a language model like GPT-4 “What colour are apples?”, it searches its vast internalized database for patterns and contexts associated with the words “colour”, “apples” and finds that “apples” are typically associated with the “colour” “red”. If you change up the context by asking “What brand colour is Apple”, it will instead study the probability between the words “brand”, “colour” and “apple” before returning the answer “white”Computation: The process of training and inferencing requires models to parse through tons of data and perform complex mathematical calculations – this runs on compute hardware like GPUs. Without sufficient computing power, training complex models and making real-time decisions would be slow or even impossible. That’s why advancements in computing technology are so crucial to the progress of AI
Overview of what AI x Web 3 stands for
The intersection of AI and Web 3.0 represents a new paradigm in the technological landscape where decentralized, distributed systems synergize with intelligent automation. It’s a world where machine learning algorithms are not monopolized by a few large entities such as OpenAI but are instead openly accessible in a permissionless manner to anyone, thanks to the underlying blockchain technology.
The ethos of this intersection involves democratizing access to AI, encouraging open collaboration, ensuring data privacy and control, and promoting equitable distribution of AI’s economic benefits. By combining the transparent, trustless nature of blockchain with the predictive power of AI, we are moving towards a future where AI benefits are widely distributed, ensuring both individual empowerment and collective advancement
In our recent podcast episode, Giza’s Co-Founder Cem even compared the potential of AI x Web 3 to the potential of smart contracts back in 2015 – we’re still extremely early and there’s much to explore. If you’re looking for a take on “what’s possible” with AI x Web 3, check out our guest post written by Catrina Wang here. The following will focus primarily on the projects with live products in the AI x Web 3 landscape.
Decentralized Compute Networks
As mentioned above, Artificial Intelligence involves hefty computational tasks, particularly during training and inferencing. Graphics Processing Units (GPUs), with their ability to perform numerous calculation simultaneously, are deployed extensively to enable quicker model training and response times than Central Processing Units (CPUs)
GPUs, therefore, play a critical role in the field of AI. As we trend towards larger and more powerful models, the demand for GPUs naturally increases as well – with estimations that GPU demand outstrips supply by a factor of 10. For context on how much computing power is needed to train a modern AI model, Meta’s LLaMA model with 65B parameters (60% smaller than GPT-3) took 21 days to train over 2,048 A100 GPUs with 80GB of RAM (typical consumer GPU is only 8GB).
The combined impact of the ever-increasing computation requirement and demand for computing power is rising costs. For reference, analysts have estimated that the GPT2 costs $40,000 to train, and its successor GPT3 model costs between $500,000 to $4.6 million to train each run. While the exact parameters of GPT4 have not been disclosed by OpenAI, its improved capabilities over GPT3 suggest that its training costs are even higher.

The capital requirements do not end at training and finetuning either. Running the model for inferencing costs money too. In fact, it costs AI companies more money to run inferences. It is estimated that GPT3 costs OpenAI close to $700,000 per day to operate – in just a week, operating GPT3 would cost more than its training cost
The rising cost and limited computing power pose the following issues:
Barrier to entry to smaller companies: High upfront costs could inhibit smaller companies from entering the field, potentially leading to a monopolization of AI innovations by a few financially robust corporations
Slower progress: Larger, more complex models might become too expensive or take too long to train, which could limit the exploration of new techniques and technologies
Mercy of centralized providers: Given that the majority of commercial computing power is owned by a few centralized providers and most AI operators rely on cloud computing, these providers wield significant influence over clients. Such dominance can lead to dependency and reduced flexibility for AI operators, potentially stifling innovation and competition
Performance degradation: Overburdened servers may cause inferencing processes to take longer or fail midway. Models may also need to limit the size of their inputs and outputs, potentially compromising their effectiveness and accuracy.
Cost transfer to end-users: The financial burden of expensive computing resources might ultimately be passed on to end-users. This could result in increased pricing for AI-powered products and services, potentially making them less accessible for the wider public
Decentralized Compute Networks (DCNs) believe that the solution to bridge the gap between computing demand and supply lies in utilizing the underutilized computing resources around the world. This can be done by connecting those seeking computing resources to those with idle computing power directly with one another via peer-to-peer networks or through platforms that aggregate computing power, thereby offering lower prices compared to centralized providers
Recently, DCNs like Render Network and Akash Network (disclosure: as of writing editor holds $AKT) have been making waves on Twitter for being “AI Coins”. However, there are a few things you should know before you get too excited and all in
Commercial-Scale Use of DCNs in AI is a Work In Progress
Many projects are indeed preparing for the eventual launch of providing computing power for AI workflows, but most are not live or at least not widely used yet. While we are still ways from solving AI computing issues with DCNs, we can still study which project is likely to be at the forefront (based on their previous performance) and compare their progress.
Most live DCNs are General-Purpose DCNs that serve various use cases, from simple web hosting to hosting games and blockchain nodes. Popular general-purpose DCNs include Akash Network, Flux and Golem.
Common across these 3 platforms is that their computing network currently consists of CPUs, not GPUs. This means that it is not their current CPU network but a separate (upcoming) GPU network that will be used to supply computing power for AI workflows.

While a direct comparison is difficult, it is likely that Flux has the greatest CPU power among the 3 currently - potentially signaling market confidence and could be used as an indicator for its future GPU network performance. In addition, Flux has a head start as the miners who secure their blockchain network already own the necessary GPU hardware. On top of securing the network, Flux plans to utilize the 200,000 GPUs in its network with its new Proof-of-Useful-Work algorithm to offer computing power for AI and other compute-intensive tasks
Unlike the others, Render Network already has an active GPU network. Render is a DCN specializing in rendering, which is the process of generating a final image or animation from a specific scene or model. Its network consists of centralized node operators such as AWS, Google and Microsoft that provide commercial-grade GPU power and decentralized providers who are individuals with additional compute capacity. In 2022, its GPU network supplied the computing power to render approximately 10 million frames, equivalent to 2200 hours of video footage.
On top of being ahead with the GPU network, Render has begun offering Stable Diffusion, a text-to-image AI model which allows creators to generate images simply based on text prompts, with Render’s GPU network providing the necessary computing power. However, it is still premature to assess the reliability of DCNs (and Render) in handling commercial-scale AI workloads, as the feature was only limited to Render creators and can operate on most consumer-grade gaming computers. Nonetheless, it was a good showcase of future possibilities and how Render could cater to such computation demands.
Here’s the current status and upcoming developments for each DCN:
Render – GPU network is already active. Begun offering computing power for AI rendering jobs but has hinted at possible expansion to large-language AI models in the future. Recently launched a Request for Compute feature for jobs outside of rendering and put out a proposal to expand Render Network’s use case through an external API that will allow users to access Render nodes for machine learning, training, inference, and finetuning functions
Akash – Recently concluded its GPU Testnet with over 1,300 participants with NVIDIA GPUs including H100s, A100s and more. Some interesting use-cases the community has tested with the GPU Testnet. The proposal to bring the GPU network to mainnet has passed, expected to go live on 31st August 2023. Proposal for open-source access to GPUs, stablecoin settlement, and take rate is currently still in the midst of voting as of 28th August
Golem – Launched GPU computing proof-of-concept using Stable Diffusion back in February (though Golem themselves provided GPU). Mentioned briefly plans to offer GPU rental service on Golem Portal
Flux – In the latter part of 2023, Flux will switch over to a Proof-of-Useful-Work algorithm (developed with University of Geneva Applied Science), where the 200,000 GPUs securing the Flux network can also be used towards useful work like AI and other compute-intensive tasks.
Another key point to note is that while these DCNs are effective for finetuning and inferencing, they are not as suitable for training purposes.
Most DCNs are Suitable for Inferencing and Finetuning, Not Training
The initial training of AI models is typically a much more resource-intensive process involving more significant volumes of data and more complex computations than finetuning and inferencing.
Most DCNs would not be able to offer the computing power necessary for training large models because computing power is typically limited to the supply of an individual provider due to its peer-to-peer structure – Akash’s founder, Greg Osuri, has also acknowledged that Akash is optimal for inference and finetuning, not training.
Even in Render’s case, whereby computing power is committed to the entire network, there’s difficulty with running large training jobs because they are difficult to “split” across different GPU machines. Unlike 3D rendering jobs, which are embarrassingly parallel, AI jobs are difficult to parallelize because of the practical challenges associated with synchronizing and coordinating distributed computations that are intricately dependent on one another. Training is also harder to parallelize than inference, as updated model parameters (weights) have to be exchanged between nodes.
From an investor’s point of view, catering primarily to the inferencing market is not an issue given that the inferencing market is likely a larger market compared to training – Nvidia’s CEO Jensen Huang estimated that 80-90% of the AI cost is devoted to inferencing at conference back in 2019. This view is further substantiated with GPT3’s inference costing more than its training that we shared above. Thus, prioritizing the inferencing market could present a more substantial opportunity for returns on investment in the AI space, whereas focusing on training is likely more critical for AI progression.
“Upcoming catalysts? Larger market opportunity? Say no more I’m all in!”
Well… not quite yet…
Decentralized Networks Specializing in AI/Machine Learning
Till now, we’ve discussed general-purpose networks, which aren’t specifically designed for machine learning and AI. As previously hinted, leveraging decentralized networks for training and inferencing in AI comes with unique challenges and AI-specialized decentralized networks aim to address these issues. Without getting too technical, let’s briefly highlight some of these problems
Verifiability: While centralized solutions rely on reputation for trust, users of decentralized networks need to ascertain that the computations performed by individual nodes are correct and reliable in a trustless manner. This entails creating an efficient and robust mechanism to verify the integrity of results, ensuring that untrustworthy or malicious nodes cannot disrupt the accuracy and dependability of the network’s output
Heterogeneity: In a decentralized AI network, computation resources can significantly vary across different nodes, in terms of hardware capabilities, available bandwidth, and latency. Managing this diversity effectively to ensure optimal and fair use of resources across the network, without compromising the efficiency and speed of computations is a significant challenge
Gensyn and Bittensor are two decentralized AI networks that aim to address these challenges and streamline the AI computation process in a decentralized environment
Gensyn is a Layer 1 protocol attempting to solve the parallelization and verifiability for AI workloads. It leverages smart contracts and combines a probabilistic proof-of-learning with a graph-based pinpoint protocol alongside a staking and slashing incentive system.
In layman's terms, this means Gensyn aims to break down typically unparallelizable, large AI workloads into smaller units and distribute them across the network. This approach optimizes the computational power pledged to the network, which allows for compute jobs that would otherwise be challenging in a traditional peer-to-peer structure. Moreover, users do not have to rely solely on reputation; instead, they benefit from verifiable computations, which can help break down skepticism associated with decentralized networks.
Gensyn is still in its testing phase, but the team has estimated that users will only pay approximately $0.40 per hour for NVIDIA V100-equivalent computation on Gensyn, which is 80% cheaper than AWS.
On the other hand, Bittensor’s machine-learning network is already live. Beyond just contributing computing power, Bittensor participants also contribute machine learning models to a decentralized, self-evolving ecosystem. It combines mixture of experts and knowledge distillation techniques that allows for a permissionless and open market where models can be finetuned, shared, and monetized according to their value in achieving specific objectives. Bittensor’s primary focus is not on providing computing power, but on incentivizing the collaborative creation, enhancement, and application of machine learning models. According to the team, Bittensor’s network currently consists of 3,400 independent Large Language Models across 2 subnets.
Summary of Decentralize Compute Networks
As we enter the era of Artificial Intelligence, we stand on the precipice of an immense market opportunity for GPU computing, with the industry estimating the market size to grow from $39 billion in 2022 to $594 billion by the year 2032. Coupled with the current GPU shortage and elevated costs from centralized providers, this scenario presents compelling incentives to explore decentralized alternatives
Bootstrapping GPU providers is also likely to be a non-issue for these decentralized networks, as there are tons of miners with GPUs after the Ethereum Merge looking for a network to contribute to. However, sufficient incentives are still required to incentivize them to contribute to such networks. In the short-term, AI-specialized networks that are already optimized for AI applications, such as Bittensor, Gensyn, and others, are poised to secure wider adoption. That said, the AI-specialized networks and non-AI specialized GPU networks are not necessarily competitive but could be collaborative. In the longer term, we will see these specialized networks funnel computation jobs to the generalized GPU compute networks – something that is already being explored
One crucial aspect to bear in mind is that latency is an inherent characteristic of decentralized networks, offset by the cost advantages they provide. In light of this, early adopters of these decentralized networks are likely to be organizations that either require less computationally-intensive, non-real-time tasks or those who are more cost-conscious.
Similarly, finetuning and inferencing jobs that are less computationally intensive are more suitable and will be the primary source of demand for decentralized computing. This is also not a cause for concern, given that the market for finetuning and inferencing is expected to be 4x of training.
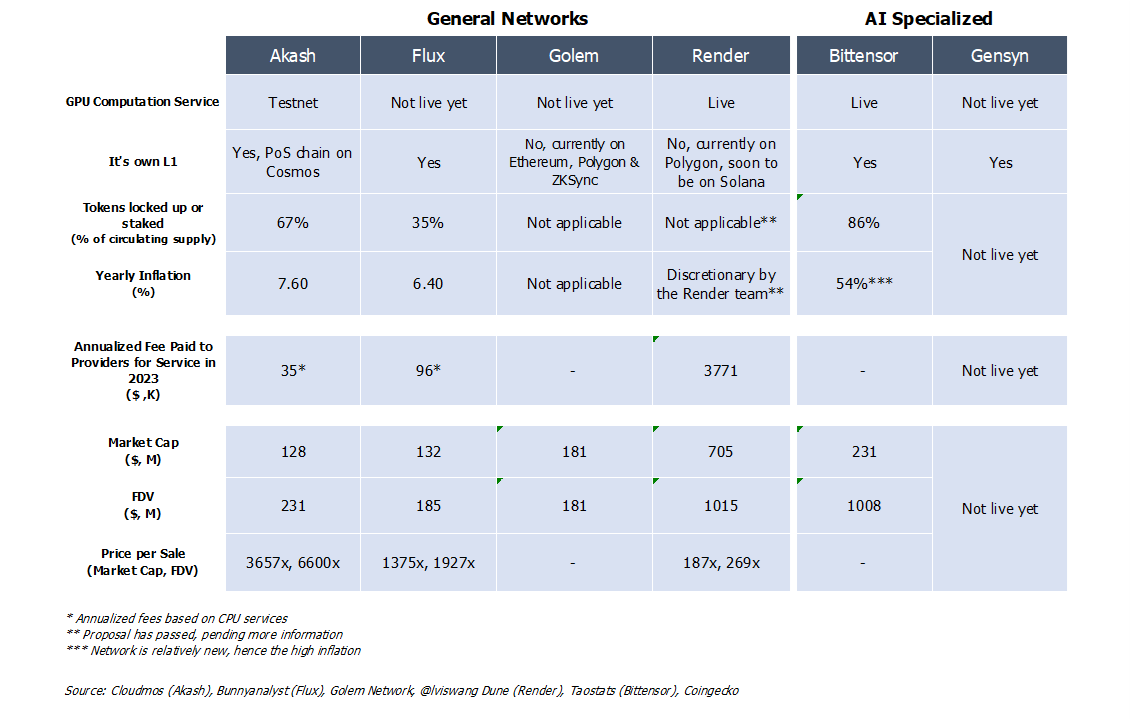
While the promise and potential of decentralized GPU networks are undeniably massive, investors and builders alike should proceed with prudence. Existing decentralized CPU networks, despite similarly competing in a massive market opportunity and sharing similar narratives of decentralization and lower costs, have yet to claim substantial market share from centralized providers. This is evidenced by Akash and Flux’s projected performance of only facilitating less than $100K of computing jobs each, despite the industry being worth $546 billion in 2022. Similarly, Render Network, operating in the $1.6 billion rendering market, has also struggled to secures substantial market share
For investors, this should underscore the necessity of comprehensive due diligence when navigating the decentralized compute space. Market size and the disruptive narrative are important, but so are actual execution and adoption. It is crucial to assess these networks’ usability, technological maturity, and real-world application.
Decentralized AI builders, on the other hand, can derive valuable insights from these examples. It becomes evident that to compete effectively with established centralized providers, decentralized solutions must address not only cost-efficiency but also reliability, speed, and user-friendliness. Addressing these areas could potentially result in a better market position and increased adoption, leading to a healthier ecosystem for the decentralized AI and compute industry.
Decentralized Data Networks
Data is the lifeblood of AI. At its core, training an AI model involves feeding it with data so that it may recognize patterns, which it uses as the basis for making decisions or predicting outcomes. In this case, the higher the quality of data and the more extensive the data set an AI model can access during training, the more accurately it can identify patterns and make predictions.
The typical data gathering process involves web scraping, going through old databases, directly sourcing from sites such as OpenML or Amazon Datasets which has Common Crawl that scraped 50 billion web pages, or purchasing from data marketplaces such as Snowflake and Axciom. After procuring data, they need to be cleaned, labeled, organized, and stored efficiently
Currently, various issues are present concerning data:
Running out of data: Researchers have found that (public) data stocks across language and image types are growing much slower than training dataset sizes and estimate that the supply of high-quality language data (those that have passed “usefulness of quality filters”) will deplete as soon as 2026. Without (new) data, AI researchers cannot scale their models, and AI progression will slow down.
Difficulty in procuring quality data: 53% of respondents surveyed by International Data Corporation cited the lack of adequate volume of quality data as a main challenbge to implementing AI solutions
High cost of data in time spent and money: Capturing internal proprietary data requires companies to invest in proper infrastructure and maintenance, while external data is fragmented across thousands of marketplaces and may come in different formats. Furthermore, given the importance of data, organizations spend the largest percentage (45% to 90%) of their total time in the AI lifecycle on data collection and preparation. This also directly translates into higher costs, as data sourcing and preparation consumes an average of 58% of an organization’s AI budget (excluding computing)
Decentralized Infrastructure for Data Sharing
First released in 2018, Ocean Protocol is the more established data infrastructure layer in Web 3 that provides the tools and platforms needed for people to best provide, share and monetize data (not to be confused with data storage like Filecoin
Core features of Ocean Protocol include:
Enhancing privacy: Ocean allows data owners to retain privacy on their datasets while allowing data users to train or run models with its Compute-to-Data feature. On top of maintaining privacy, this improves access to otherwise proprietary data as data owners have the assurance that data will not leave their premises, nor will they incur liability since it is GDPR compliant. Data sourcing costs are also reduced since data does not move across servers.
Incentivizing data curation: Data curators stake veOCEAN tokens (native Ocean Protocol token that’s been locked) with datasets to signal the dataset’s quality. In return, data curators earn rewards based on the dataset’s performance i.e. how much was spent to purchase or interact with the dataset
Facilitating decentralized data consortiums: Datasets are minted as an on-chain NFT, which specifies who the owners are, who gets a share of the revenue, different layers of access, and more. Data NFTs help coordinate data DAOs’ activities, as everything can happen trustlessly. Individual users may also mint their data as an NFT and share it with a consortium to earn rewards
Data Provenance: Ensure data transparency, enforce intellectual property rights, and combat deepfakes
Cost reduction: Ocean makes it easier to share data trustlessly and allows data owners to deal directly with data buyers via Ocean Marketplace or other decentralized data marketplaces, thereby reducing costs
Performance Analysis

Based on an (unofficial) Dune dashboard, the amount of paid data transactions (datatoken transfer) and data sets created (datatokens created) has failed to sustain beyond its initial hype in Q4 2020. For the past year, on average, fewer than 5 transactions and datasets were created each month on Ocean Marketplace.
Theoretically, Ocean Protocol should capture and scale alongside the projected 8% CAGR of the data market from 2021 to 2026, thanks to the exponential demand for data with the AI boom
However, Ocean Protocol’s performance shows otherwise, highlighting that they are facing difficulties attracting data providers AND data consumers after the original launch hype and network rewards in late 2020 – why is this happening?
Possible reasons for underperformance
Below we offer some possible reasons for Ocean Protocol’s underperformance, which may provide insights into the gaps that the Web 3 data industry has to fill
On the data supply side, the value proposition is not appealing enough:
Finding demand is not inherently an issue for data providers: For data owners willing to sell their data, there are thousands of data brokers to partner with. Similarly, data brokers are not facing a demand issue. While removing intermediaries and lower platform fees may allow them to exchange data for more money, the ease of doing so is also essential. The use of blockchains in decentralized platforms is a potential barrier.
Privacy is not the main issue: For those unwilling to share their proprietary data, privacy is unlikely to be the issue. The issue likely lies in the lack of incentives as they likely see more value in keeping it private than sharing. In any case, Ocean’s Compute-to-Data feature, also known as Confidential Computing in data science, is not necessarily inherent to decentralized platforms
On the data demand side, the cost tradeoff is insufficient:
Data quality concerns: While the current data curation mechanism incentivizes participation and high-quality datasets, it may not be an effective signal to quality nor actively discourage low-quality datasets. Furthermore, not all datasets offer previews to data buyers and data providers are identified mainly by their wallet address. Data consumers much rather rely on centralized data broker’s reputation
Lack of standardization: Centralized data brokers typically standardize the data they collect i.e. clean and format it so that it is consistent and easy to use. This is crucial as it makes it more convenient for data consumers – this is missing with decentralized marketplaces like Ocean Protocol, which is an issue given the heterogeneity of data sources.
As we look to the future, the integration of blockchain technology in the realm of AI is becoming increasingly vital, and several major corporations are starting to realize its potential. Ocean Protocol, for instance, has been chosen to construct the data infrastructure for Gaia-X, a data initiative that has garnered participation from various European ministries. Mercedes Benz Singapore has also developed a decentralized data marketplace known as Acentrik using Ocean Protocol.
The success of these large corporations in using Ocean Protocol will likely encourage more suppliers to participate in this emerging field. At the same time, Ocean Protocol will have to do more work incentivizing the formation of data DAOs.
On the demand side, Ocean Protocol can also improve data-quality confidence by introducing slashing to penalize poor-quality datasets and curation or making it easier for data consumers to purchase datasets with credit card onramps.
While strategies like increasing the formation of data DAOs and boosting data quality through penalties for poor datasets can help to balance the data economy, a more radical shift might be necessary to truly democratize the benefits of data generation. On top of making data more accessible and reliable for corporations, we might need to reconsider the very nature of data ownership itself. This leads us to an emerging solution that seeks to rebalance the scales of data value: incentivizing data sharing.
Incentivizing Data Sharing
Every day, an incredible volume of data is generated as people interact with digital devices and platforms. From the music we listen to on streaming platforms, the purchases we make online, and the locations we visit, these seemingly mundane activities contribute to a vast, ever-growing digital footprint.
This data is more than just digital noise. It is a valuable resource that can provide deep insights into consumer behaviors, preferences, and trends. Companies can analyze this data to improve their products, tailor their marketing strategies, and make informed business decisions. It is the fuel that powers AI algorithms and predictive models, enabling them to provide personalized recommendations, improve user experiences, and even predict future behaviors.
However, while large tech companies like Facebook and other platforms benefit immensely from this data, the individuals who generate it — the users — typically see none of the financial rewards. These companies collect, analyze, and sell user data and profit enormously in the process.
What if we could enhance access to data and make it more equitable for the users at the same time? Enter data incentivization networks.
At a high-level, data incentivization networks allow users to collect, utilize and exchange their data for rewards. They function on the principle of data ownership, promoting a fairer exchange by giving users a share of the financial benefits derived from the data they produce.
Some live examples include:
DIMO: Empowers vehicle owners to capture, utilize and sell their vehicle data to relevant entities such as automotive insurance, fleet management, and automobile companies. The overarching vision is not limited to data exchange, but also aims to build an ecosystem where vehicle data can unlock innovative products, such as decentralized ride-hailing services or DeFi-based car insurance and loans. There are approximately 17,000 contributing vehicles to date.
Hivemapper: Decentralized mapping network that similarly involves vehicles like DIMO, but collects street-level imagery and map data instead of vehicle data. The goal is to construct a superior digital map that rivals giants like Google Maps. The data may also be purchased by businesses that rely on accurate maps for operations (e.g Uber) or those developing autonomous vehicles. Remember the Google Captcha that you have to complete before accessing a site? That is a process in AI known as Reinforcement Learning from Human Feedback (RLHF), wherein human feedback is used to further train the model. Instead of doing it for free, Hivemapper pays contributors to train its AI to recognize objects in the imagery data like road signs or speed limits. They have since onboarded 16,500 contributors.
Undoubtedly, these protocols help enhance access to data, and the market opportunity here is huge – vehicle data industry is expected to be worth $250 - $400 billion by 2030, while the geospatial analytics market could hit $256 billion by 2028. What’s more, beyond simply selling data, both protocols also have ambitions to build expansive ecosystems that utilize the data they collect.
At its core, the concept is straightforward – a broader user and database equates to more valuable data and increased revenue for the network. But it prompts a critical question: Are these networks, built around token incentives, effective at attracting users and sustainable in the long-term?
Performance Analysis

Since their token launch, DIMO and Hivemapper have garnered roughly 17,000 contributors each and have issued cumulative incentives worth $4m and $1m respectively based on today’s token prices to onboard and reward users for their contributions.
At first glance, DIMO’s incentive seems ineffective at onboarding users when considering it as data acquisition costs. Otonomo, one of the leading traditional platforms for mobility data listed on NASDAQ, has reported in its annual report that it processes 4 billion data points daily from over 50 million vehicles. The massive database had only cost them $2.25 million in 2022 to procure, equating to approximately $0.05 per vehicle versus DIMO’s annualized cost of $402 per vehicle.
However, this overlooks not only the qualitative difference between Otonomo and DIMO’s vehicle data but also the primary goal of DIMO. Beyond acquiring vehicle data to sell it, DIMO is trying to build an open ecosystem that allows vehicle owners to utilize their data to gain access to higher quality services such as more accurate valuation of vehicles, lower insurance fees from better risk underwriting, and more. In this case, each DIMO-connected vehicle’s potential annual revenue and lifetime value are significantly higher than the $0.14 revenue per vehicle that Otonomo received in 2022, which potentially justifies the cost difference to onboard each vehicle.
Conversely, Hivemapper’s incentives appear to be relatively effective at incentivizing map data capture thus far. Their current rate of map data growth is approximately 8x faster than Google Street View’s during its first five years post-launch in 2007. Furthermore, Hivemapper achieves this with significantly superior cost efficiency, as contributors use their own vehicles and personally shoulder the $299 cost of the Hivemapper dashcam. With an average of 2500 weekly mapping contributors, the anticipated annual incentive fee per vehicle only amounts to $600. This is just a tiny fraction of what Google Street View would spend per vehicle, including vehicle and camera purchases, drivers’ salaries, and fuel. Even as the pace of map expansion reduces as fewer regions remain unmapped, Hivemapper’s model is still likely to maintain far superior cost efficiency.
It’s important to note that while both companies issued considerable token incentives, this doesn’t represent a traditional cash investment. These incentives, though causing token dilution, enabled DIMO and Hivemapper to stimulate user growth and data collection without a significant upfront monetary investment.

While the generated data is intended to form a vital part of their revenue streams, both DIMO and Hivemapper are still in the early stages and have not yet seen significant revenue, which is the key challenge that lies ahead for them.
As more users join, token distributions naturally increase, posing a risk of token inflation and subsequent dilution of value for token holders if not adequately managed. To mitigate this, both platforms have introduced some form of token burning which reduces circulating supply when data is consumed. However, the efficacy of this measure relies on securing a consistent stream of data buyers
There are further intricacies to their token models and value capture methods that are beyond the scope of this piece, but certainly worthy of future exploration. In the meantime, you may find more pieces on such token models in the Resource segment below.
To conclude, the tokenized approach employed by DIMO and Hivemapper presents a novel twist in incentivizing data sharing. The use of token incentives not only bolsters user growth and data collection with minimal initial financial input, but it also democratizes data access for data consumers and ensures fairer compensation for data providers and owners. The ultimate success of DIMO and Hivemapper will depend not just on the volume of data they accumulate but on how effectively they can leverage this data to create value for their customers while maintaining the trust and engagement of their user contributors.
Final Thoughts
The intersection of Web 3.0 and Artificial Intelligence (AI) presents a compelling frontier in the technological landscape. This convergence promises to democratize access to AI, foster open collaboration, ensure data privacy, and promote an equitable distribution of AI’s economic benefits. The potential of this intersection is vast, as it combines the transparent, trustless nature of blockchain with the predictive power of AI, steering us towards a future where the benefits of AI are widely distributed.
However, the path to this future is not without its challenges. One of the significant hurdles is the limitations of Decentralized Compute Networks (DCNs). Despite the promising narrative of massive markets and lower computing costs for users, DCNs, particularly those based on Central Processing Units (CPUs), have not gained meaningful traction. This lack of progress could be attributed to various factors, including the lack of confidence in decentralized platforms and the competitive landscape of the computing industry.
On the other hand, the market for Graphics Processing Units (GPUs), which are critical for AI tasks, presents a stronger push factor. The demand for GPUs currently outstrips supply, creating a pressing need for solutions that can bridge this gap. DCNs based on GPUs could potentially address this need, but their effectiveness and sustainability remain to be seen.
Data incentivization networks represent another promising development in the AI and Web 3.0 intersection. These networks allow users to collect, utilize, and exchange their data for rewards, promoting a fairer exchange by giving users a share of the financial benefits derived from their data. This approach is not only cost-effective but also makes data exchange more equitable for users. It will be interesting to see how this model applies to other verticals, such as social network data, purchase history, health data, and more.
However, these networks have yet to find substantial demand for data at the current moment. The challenge lies not only in attracting users to share their data but also in generating meaningful demand for this data. To compete with centralized alternatives, these networks will need to match or surpass them in terms of data volume. However, volume alone may not be sufficient - these networks will need to provide data that is not only substantial in volume but also offers greater depth or value. This could involve providing more detailed, accurate, or niche data that is not readily available from centralized sources.
Many more exciting AI x Web 3 use cases are still in their nascent, exploratory phase, which we will be exploring in future pieces. If you want to have a glimpse of what these use cases are, check out Catrina’s piece here.
If you’re building in this space, please reach out to us as well!
Special shoutout to all the mentioned projects for helping me understand more about what they’re doing and providing feedback on this piece!
Resources
Projects mentioned:
Gensyn: Website
DIMO: Website, Analytics 1, Analytics 2
Hivemapper: Website, Analytics 1, Analytics 2
Suggested readings
Catrina’s thesis on Web 3 x AI
Ian’s research on Render Network
Kyle Samani’s piece on Convergence of Crypto & AI
Hashed’s piece on Crypto and Reinforcement Learning from Human Feedback
Disclaimer
The Blockcrunch Podcast (“Blockcrunch”) is an educational resource intended for informational purposes only. Blockcrunch produces a weekly podcast and newsletter that routinely covers projects in Web 3 and may discuss assets that the host or its guests have financial exposure to.
Some Blockcrunch VIP posts are written by contractors to Blockcrunch and posts reflect the contractors’ independent views, not Blockcrunch’s official stance. Blockcrunch requires contractors to disclose their financial exposure to projects they write about but is not able to fully guarantee no such conflicts of interest exist. Blockcrunch itself will not buy or sell assets it covers 72 hours prior to and subsequent to the publication of a piece; however, its directors, employees, contractors and affiliates may buy or sell assets prior to or subsequent to publication of any content and will make disclosures on a best effort basis.
Views held by Blockcrunch’s guests are their own. None of Blockcrunch, its registered entity or any of its affiliated personnel are licensed to provide any type of financial advice, and nothing on Blockcrunch’s podcast, newsletter, website and social media should be construed as financial advice. Blockcrunch also receives compensation from its sponsor; sponsorship messages do not constitute financial advice or endorsement.
For more detailed disclaimers, visit https://blockcrunch.substack.com/about